
AFDKOによるOpenTypeフォントの作成
筆者はAdobe Font Development Kit for OpenType (AFDKO)を用いて、謎乃明朝というフォントを作成し公開している。謎乃明朝は花園フォントと同じくGlyphWikiのデータをもとにしている完全フリーのフォントであるが、GlyphWikiデータからの漢字のパスデータの生成においてオリジナルのKAGEエンジンを改変したものを使用している。
改変エンジンのget_sub_path_svg_fontという関数を使用すると、[0 -120 1000 880]をバウンディングボックスとしたときに適切に表示されるようなパスがSVG形式で出力される。この記事ではそこから先のプロセスについて解説する。
他に全体を通して参考になるサイトとしては以下がある。
AFDKO入門《CIDキー方式のOpenTypeフォントの作り方》 前篇:AFDKOのインストールとmergeFonts - しろもじメモランダム
一通りのことが書いてある読みやすい日本語の記事はこれくらいである。筆者もこれを参考にした。
https://ccjktype.fonts.adobe.com/wp-content/uploads/2012/06/afdko-lunde-20120625.pdf
ワークショップで使用した講義資料なので単体だとやや読みづらいが、ヒント情報の付加に関して唯一まともに書いてあった。
-
OpenTypeの仕様が日本語で記述されている。
パスの統合・単純化
これはAFDKOには関係ないが割と役に立つ話なのでついでに記載する。
Inkscapeによる統合
改造エンジンで生成した漢字パスデータはそれぞれの画が別々のサブパスで表現されており、互いに重複する部分がある。これをそのままフォントに使うこともできるが、画が交差する場所(「田」の中央とか)で白い抜けが表示されてしまうなど不具合が生じる場合がある。そこで、重複がなくなるようにパス同士のUnionを取る(統合する)必要がある。
この目的で本家の花園明朝ではClipperが使われているが、こちらはどうやら直線のみ対応で、ベジェ曲線は扱えないようである。ベジェ曲線にも使えるフリーのものはFontforgeとInkscapeがあるがFontforgeは色々と不安定なのでInkscapeを使う。
- Fontforgeは一応試したが、閉じていないパスが発生する不具合が頻発するのと、GUIだと途中で落ちる。ところで、謎乃明朝にissue(https://github.com/ge9/NazonoMincho/issues/2)が立ったが、KAGEデータの「曲げ」ストロークにおいてInkscapeの統合によって図形が消えるバグが発生していた(https://gitlab.com/inkscape/inbox/-/issues/6886 に報告済)(謎乃明朝側ではストロークの図形をあらかじめ統合された状態で生成することで回避して対応済)。Inkscapeも完璧ではないようである。
コマンドとしては
inkscape --actions="select-all;path-union" --export-type=svg input.svg
などとすると、input_out.svgが出力される。
ワイルドカード*.svgも使えるが、謎乃明朝のビルド時はかなり大量のファイルを処理するために「コマンドライン引数が長すぎる」的なことを言われてしまうのでxargsを使った(自動で分割してくれる)。
個々のsvgファイルとして処理する(出力ファイルを逐一新規作成する)ためIOが頻発して効率はあまりよくない(謎乃明朝の数万グリフに対して実行すると数十分かかる)のだが、入力ファイル単位で分ける以外で複数のパスデータをバッチ処理で統合する(例えばsvgの”path”タグごと処理するなど)方法があるのかどうかはわからなかった。分かったら誰か教えてください。
Fontforgeによる単純化
統合を行うと、(KAGEエンジン側のデザインの都合もあり)完全な直線になるべき部分が微妙な誤差のせいでほぼ直線と変わらない微妙な折れ線になってしまうことがある。また、極めて短く直線に近似できるのにベジェ曲線で表現されてしまう場合もある。こうした箇所はデータ削減やヒント(後述)の品質向上のために制御点を除いて単純化(simplify)したい。
Inkscapeにも単純化はあるのだが、やってみたところ、単純化を行うと逆に曲線部分では無駄な制御点が挿入されてしまうというバグ(報告済み→こちらに移動)があったので今回はスキップ。単純化に関してはFontforgeのほうが良さそうである。
FontforgeはSVGフォント(=単一ファイルに複数のパスを入れられる)に対応しているので、先ほどInkscapeが出力したファイルを一つにまとめてからFontforgeに入力して全グリフをSimplifyするという流れになる。あとFontforgeのGUIは割と不安定(特にWindows版)なので、対象が1000個を超えるような場合はスクリプトを組んでCUIで実行することを強く推奨する。
例:
Open($argv[1])
SelectAll()
Simplify(128+32+8, 1.1)
Generate($argv[2])
- 手元では「NaN value in spline creation」というエラーが漢字10000字につき1.5文字くらいの割合で出るのだが、該当文字を見ても特に問題はなさそうだったので放置している。
AFDKOでのフォント作成 - 基本
基本的には
素材フォント→(適宜txなどで変換した上でmergefonts)→ヒント情報無しのCIDフォント→(perl-scripts/hintcidfont.pl at master · adobe-type-tools/perl-scripts と psautohintによるヒント情報の付加)→ヒント情報付きのCIDフォント→(makeotf)→完成品の(CIDキー方式の)OpenTypeフォント
という流れになる。
「CIDフォント」「PostScriptフォント」「CFFフォント」「Type1フォント」「OpenTypeフォント」など様々な用語があるが、いずれも正確な定義が難しいものばかりであり筆者も正確に理解しているわけではないのでそこは注意して読み進めていただきたい。今回作るものは「CIDキー方式のOpenTypeフォント(CID-keyed OpenType Font)」だが、おそらくCFFフォントでもあり、PostScriptフォントでもあるのではないかと思われる。
txで使えるSVGデータ
まず、単体のSVGではフォントとして正しくtxに認識されないので、SVGフォントの形にする必要がある。具体的には、<font>タグが最も外側にある状態にする。「SVGフォント」といったときには(例えばFontforgeでフォントとして開く場合)さらに外側に<svg><defs>…</defs></svg>のようなタグが必要になる場合もあるが、これだとtxには弾かれるので注意が必要である。
(2023/12/21追記)改めて試したところ、
<svg><defs>...</defs></svg>で囲っても問題なく動いた。ただ、FontForgeが出力するSVGフォントのヘッダーの<?xml version="1.0" standalone="no"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd" >
があると動かなかったので、上記の内容はおそらくそれを勘違いしたものと思われる。なお、このヘッダがなくてもFontForgeは正しくSVGフォントを開けるが、
<svg><defs>...</defs></svg>がないと開けないので、<svg><defs>...</defs></svg>は付けてヘッダーは無しで保存しておくのが最も良さそうである。txのエラーメッセージは全体的にあまり丁寧ではなく、例えば入力のsvgに何かおかしい点(※ただしtxによる主観的評価)がある場合は
(svr)などとしか表示してくれない。デバッグモードもなさそうなので、根気強く原因を探すしかない。(svr)のような形式の出力については、おそらく最初の二文字(ここではsv=svgだが、cf=cffなどもある)がフォーマットを表し、最後の一文字はrがerror、wがwarningを表すようである。
そもそもAFDKO自体に「Adobe社内の業務用ツールが形だけ一般公開されている」ような雰囲気を感じなくもないような…
例えば以下は正しくtxに認識される入力のsvgである。
<font horiz-adv-x="1000">
<font-face
font-family="Untitled1"
font-weight="400"
font-stretch="normal"
units-per-em="1000"
ascent="880"
descent="-120"
bbox="0 0 1000 1000"
underline-thickness="50"
underline-position="-100"
/>
<missing-glyph horiz-adv-x="1000" d="M500 300l150 -300l-300 0zM650 760l-150 -300l-150 300l300 0zM730 760l0 -760l-190 380zM270 760l190 -380l-190 -380l0 760zM200 830l0 -900l600 0l0 900l-600 0z"/>
<glyph unicode="0" horiz-adv-x="1000" d="m-100,-100l100,0L0,100C0,200 200,0 200,200 m100,200 c 300,0 0,300 300,300 Zm-150,-150 c 200,100 -100,0 0,100 l-300,-200 l100,200 z"/>
<glyph unicode="S" horiz-adv-x="500"/>
<glyph unicode="D" horiz-adv-x="1000"/>
</font>
今回はsvgを素材としてのみ使用する(フォント名などは後で設定する)のでfont-faceタグの中身はあまり気にしなくてよいと思うが、フォントの高さ範囲を決めるascentとdescentは一応正しい値を入力してある。OpenTypeでは通常このようにフォントの高さは1000とする。
以降がフォント本体のデータで、パス(d属性)と水平方向の幅(horiz-adv-x属性)をそれぞれ指定する。
missing-glyphは普通のフォント用語でいうと.notdefにあたるもので、文字が無かった時に表示されるいわゆる「豆腐」のことである。他のフォント形式に変換するとこのグリフが.notdefに割り当てられることになる。このsvgではU+303F(〿、□の中に×が入った形)のような図形が入っている。
それ以降のglyphタグではunicode属性によりどの文字を使用するかを設定している。SやDのようにd属性がない場合は空白(スペース)を表すことになる(逆にd=””などと書くとエラーになったはず)。幅を見ればわかる通り、Sが半角スペース、Dが全角スペースである。
d属性の解釈について
txによるd属性の解釈はものすごく行儀が悪く、エラーメッセージを出さない割に明らかに仕様を満たさない挙動を連発する。
- txの挙動を迅速に確かめるには、
tx -pdf input.svg > output.pdfとpdfに変換して見るのがよい。 - 以下の不具合に関する具体的な報告はなさそうであるが、[tx/SVG] Replace homemade XML parser with LibXML2 for SVG parsing · Issue #1567 · adobe-type-tools/afdkoは関係がありそうなのでこれがfixされれば治る可能性がある。
txの1.3.0(2023年1月現在で多分最新)に関して挙動をまとめる。
まず、正しく解釈できると思われるのは以下の命令である。
- M(絶対座標によるパス開始点の指定)
- L(絶対座標による直線描画)
- l(相対座標による直線描画)
- C(絶対座標による3次ベジェ曲線描画)
- z, Z(パスを閉じる)
問題なのはc(相対座標による3次ベジェ曲線)で、本来は現在の点が(x, y)であるときにc x1,y1 x2,y2 x3,y3とすると(x, y)→(x+x1, y+y1)→(x+x2, y+y2)→(x+x3, y+y3)という3次ベジェ曲線が描画されるべきであるが、txでは(x,y) → (x+x1, y+y1) → (x+x1+x2, y+y1+y2) → (x+x1+x2+x3, y+y1+y2+y3) という意味に解釈される。
似たような問題として、パスの開始点(最初やzの直後で使用する)でm(相対座標指定)を使用する場合は、本来は絶対座標として解釈されるべきであるが、txでは直前の座標(zの直前)からの相対位置で計算される。なお、フォントの描画においては必ず閉じたパスを使用する(多分)のでパスの描画途中でMやmを使用することはありえないが、仮に使用した場合、(txでは)その直前にzを付加したのと同じ挙動をするようである。
そして、以下には対応していない。
- V, v, H, h(絶対/相対座標による垂直/水平な直線の描画)
- Q, q(絶対/相対座標による2次ベジェ曲線描画)
これらはそれぞれL, lとC, cに容易に変換できるので、そのようにしてから渡すべきである。
さらに、svgではデータ量の圧縮のため直前と同じ命令を使用する場合はl 100,100 l 200,200と書くかわりにl 100,100 200,200などと略することができるがこれにも対応していない(余ったパラメータは余計なものとして無視される)。
また、svgの仕様では座標データの数字において指数表現(1.2345e-6のような)が許容されているが、これにも対応していない((svr)となる)。
謎乃明朝で使用したsvgに関しては、元データでM,C,Lのみ使っていたおかげかinkscapeの出力でもそれら以外が入ることはないようだったが、指数表現に関してはごく稀に(謎乃明朝全体でも10個以下程度)紛れ込んでいたのでsed -r "s/ -?[0-9]\.[0-9]*e-[0-9]+ / 0 /g"で0に変えた。小数に直すのが筋かもしれないが、OpenTypeではそもそも座標が整数に丸められる気がするのでこれでいいはず。
- Inkscapeが相対座標を使用するかどうかは設定で変えられるらしい。参考: Is there a tool to convert SVG line paths from absolute to relative? - Stack Overflow
FontForgeの出力の修正
FontForgeで出力されるsvgにはlやcに加えてhやvなども(元データになくても)入ることがあり、これはtxが読めないので修正する。あとtxには関係ないが、PostScriptアウトラインの向きはFontForgeが出力するSVGのアウトラインの向き(=TrueTypeのアウトラインの向き)と逆なので、この段階で修正しておくとよい。この2点の修正は謎乃明朝の生成スクリプトではhttps://github.com/thednp/svg-path-commanderにやらせている。
txによる変換
この次で使用するmergefontsは、複数のフォントをマージするコマンドであるが、より正確には「親」となるフォントに「子」となるフォントを統合するコマンドである(ヘルプにも書いてある)。上記のようなsvg形式のフォントは「子」にはなれるが「親」にはなれない。
そこでtxコマンド(fonttoolsのttxと名前が似ているが全く異なるものなので注意)を用いてsvgを「親」として使えるフォーマットに変換する。この際の出力は、-ps(PostScript形式)、-cff(CFF形式)、-t1(Type1形式)などいくつかのオプションが選べるが、psautohintでヒントを付ける方法を筆者が発見できたのは-t1を使った場合のみであった。ヒントを付けないのであれば-cffでも問題なくこの記事の最後まで進むことができる。-psも-cffと同じだったと思う。
ちなみにmergefontsは子としてsvgが指定された場合にはそれを読むために内部的にtxを使用するため、子にしても親にしてもtxが読めるsvgを指定する必要がある。
謎乃明朝では、.notdefや空白など一部のシステムグリフ的なものだけを含むsvg(上記のsystem.svg)を親フォントとしてまずType1形式に変換したあと、子フォントとして漢字グリフを統合することにしている。
従ってコマンドとしては以下のようになる。
tx -t1 system.svg > system.pfa
参考までに、system.pfaの最初のほうは以下のようになっている。
%!FontType1-1.1: Untitled1
%ADOt1write: (1.0.35)
%%Copyright: Copyright 2023 Adobe System Incorporated. All rights reserved.
%%BeginResource: font Untitled1
12 dict dup begin
/FontType 1 def
/FontName /Untitled1 def
/FontInfo 4 dict dup begin
/FullName (Untitled1) def
end def
/PaintType 0 def
/FontMatrix [0.001 0 0 0.001 0 0] def
/Encoding 256 array
0 1 255 {1 index exch /.notdef put} for
def
/FontBBox {-100 -100 950 1050} def
end
currentfile eexec BAB431EA06BB0A1031E1AA11919E714AC6968FC4C8AFEB
5F1C717DAFACA48FA00303519D5ACA187D3A7A07245E6211EF0746489B63BDB8
0250FD69171FFE98581843A94F9CCED81A25205CD6D774793B21300079565F0A
...
mergefonts
次にmergefontsを使ってCIDフォントを作る。CIDフォントを作る場合は、コマンドの構文は以下のようになる。
mergeFonts -cid [cidfontinfo] [output] [font1.map] [font1] [font2.map] [font2] ...
cidfontinfoはフォントに関していくつかの情報を設定するファイルで、今回は以下のものを使用する。
FontName (NazoMin)
FullName (NazoMin Unknown)
FamilyName (NazoMin)
Weight (Unknown)
version (1.000)
Registry (Adobe)
Ordering (Identity)
Supplement 0
AdobeCopyright (Public Domain)
細かい部分の効果はわからないが(詳しくはAFDKO入門《CIDキー方式のOpenTypeフォントの作り方》 前篇:AFDKOのインストールとmergeFonts - しろもじメモランダム)、とりあえずこれで問題なく先に進めるだろう。FontName(Postscript名)の「NazoMin」の部分は後で使用するので覚えておくこと。FullNameとFamilyNameについては最終的にどのように反映されるのかよくわかっていない。
- Postscript名は、フォントの名前の一種であるが、あまりユーザーが目にすることはない。Postscript名では、空白を使用してはいけない。たとえばsource-han-code-jp/cidfontinfo at master · adobe-fonts/source-han-code-jpのようにハイフンに置き換えられていることが多い。また、「+」は禁止ではないようだが、今回使用するhintcidfont.plは対応していない。フォント名に「+」が入っている代表的なフォントである「M+フォント」の一種M+ 2m regular fontにおいても、Postscript名は「mplus」となっているようである。
outputで指定するファイル名は何でもいいが、そのままではまだ使えない「生」のCIDフォントということで「.raw」という拡張子を使う場合もあるようである。今回であればType 1が出力されるので.pfaとしてもよいだろう。
mapファイルと素材フォント
では、残るmapファイルと素材フォントの部分について解説する。三点リーダ...で示した通り、この[font1.map] [font1]のペアはいくらでも多く指定してよい。この部分がフォントの本体部分を形作ることになる。
最初のペアとして指定されたものが前述の「親フォント」ということになる。ここにType1フォントを指定すれば出力もType1になるし、CFFフォントを指定すればCFFになる。
今回は親フォントとして先ほどのsystem.pfaを使用する。
以下がそれに対応するmapファイルの例(system.map)である。
mergeFonts NazoMin-System
0 .notdef
1 S
633 D
8720 S
ファイルの最初にはこのようにmergeFontsという語が必要であり、その後にFDArray要素(この用語は後のヒント情報付加のところでまた出てくる)の名前を書く。ここではcidfontinfoで使用したNazoMinという(任意の)識別子にハイフンを付加してさらに別の(後でも使用する任意の)識別子であるSystemを追加したNazoMin-Systemという名前を指定している。このようにしないと、ヒント情報を付加するスクリプトであるhttps://github.com/adobe-type-tools/perl-scripts/blob/master/hintcidfont.plが正しく使えない。これはどこを見てもあまりはっきりとは書かれおらず、最終的にスクリプトのソースを読んでわかったことなので注意が必要である(スクリプトの説明をよく読むと一応「the CIDFontName plus a unique identifier」などと書いてあるのだが、ハイフンを間に入れるという説明は全くない)。ただし、これはそうしないとこのスクリプトが使えないというだけであって、CIDフォントの仕様上必要というわけではない(多分)。ただ実際、多くのCIDフォント(例えば源ノ角ゴシックなど)ではこのような命名がされている気がする。
2行目以降が、CIDからグリフへの対応を記述したものである。
- 以下のように、x番目のCIDという意味で「CID+x」と書くことが多い
まず2行目で、CID+0に先ほどのSVGのmissing-glyphが割り当てられる。CIDフォント(少なくともCID形式のOpenTypeフォント?)ではCID+0は必ず含める必要があり、これが「豆腐」グリフとなる。
3-5行目により、CID+1とCID+8720には半角スペース(ただし後者は縦書き用として使用する。後のmakeotfの節も参照)、CID+633に全角スペースが割り当てられる。これはAdobe-Japan1に従ったものであるが、Adobe-Japan1準拠のフォントを作るのでなければ(CID+0とは違って)必ずしもこのようにする必要はないはず。ただ、(現在はリンク切れとなっているのでweb archiveのURLを貼るが)花園明朝OTを0.510に更新、IVD 2012-03-02版に対応 - しろもじメモランダムにおいて、「Windowsでは、CFFアウトラインのOpenTypeフォントのGSUBテーブルにvrt2 featureが定義されていないのにvhea/vmtxテーブルがあると、OSに不正なフォントして弾かれます。」との情報があり、花園明朝OTではこれに対応するためにこの3グリフを追加したとされている。そこで謎乃明朝でも一応この通りにしている(ただし謎乃明朝+では漢字と範囲を分けるためにCIDの割り当てを1, 633, 8720からそれぞれ1, 100, 101に変えている)。
このファイルを見てわかる通り、ソースフォントの同じ文字を複数のCIDで使用しても構わない(その分データは増えるはず)(Adobe-Japan1/README-JP.md at master · adobe-type-tools/Adobe-Japan1 の 「重複した漢字グリフ」もその一例)。CIDの部分は0000,00001のように先頭にいくつか0が付いていても構わない。
次に、「子」として使用するmapファイルとSVGファイル(今回は子は1つだけなので1つずつ)をそれぞれ見てみよう。謎乃明朝には数万文字の漢字が収録されているが、ここでは解説に適した6グリフのみ収録したサンプルを使用する。
mergeFonts NazoMin-Ideographs
14197 u8279-j
14198 ufa5e
14199 ufa5d
24000 u20000-jv
24001 u20000-ue0101
24002 u20000-ue0102
<font id="Untitled1" horiz-adv-x="1000" >
<font-face
font-family="Untitled1"
font-weight="400"
font-stretch="normal"
units-per-em="1000"
ascent="880"
descent="-120"
bbox="0 0 1000 1000"
underline-thickness="50"
underline-position="-100"
/>
<missing-glyph horiz-adv-x="1000" d="M50,0l900,0l0,533l-900,0 z M100,50l0,433l800,0l0,-433z"/>
<glyph glyph-name="u8279-j" d="M 321.5 247.15039 L 321.5 411.21289 L 43.25 411.21289 L 43.25 436.41211 L 321.5 436.41211 L 321.5 562.9375 L 321.5 578.6875 L 321.5 600.38867 L 383.93359 588.48633 C 415.96232 582.32437 417.82989 565.93743 384.5 555.52148 L 384.5 436.41211 L 615.5 436.41211 L 615.5 562.9375 L 615.5 578.6875 L 615.5 600.38867 L 677.93359 588.48633 C 709.96232 582.32437 711.82989 565.93743 678.5 555.52148 L 678.5 436.41211 L 843.34961 436.41211 L 893.75 486.8125 L 956.75 436.41211 L 956.75 411.21289 L 678.5 411.21289 L 678.5 272.34961 L 615.5 247.15039 L 615.5 411.21289 L 384.5 411.21289 L 384.5 272.34961 L 321.5 247.15039 z"/>
<glyph glyph-name="ufa5e" d="M 279.5 247.15039 L 279.5 411.21289 L 43.25 411.21289 L 43.25 436.41211 L 279.5 436.41211 L 279.5 562.9375 L 279.5 578.6875 L 279.5 600.38867 L 341.93359 588.48633 C 373.96232 582.32437 375.82989 565.93743 342.5 555.52148 L 342.5 436.41211 L 360.34961 436.41211 L 410.75 486.8125 L 473.75 436.41211 L 473.75 411.21289 L 342.5 411.21289 L 342.5 272.34961 L 279.5 247.15039 z M 657.5 247.15039 L 657.5 411.21289 L 526.25 411.21289 L 526.25 436.41211 L 657.5 436.41211 L 657.5 562.9375 L 657.5 578.6875 L 657.5 600.38867 L 719.93359 588.48633 C 751.96232 582.32437 753.82989 565.93743 720.5 555.52148 L 720.5 436.41211 L 843.34961 436.41211 L 893.75 486.8125 L 956.75 436.41211 L 956.75 411.21289 L 720.5 411.21289 L 720.5 272.34961 L 657.5 247.15039 z"/>
<glyph glyph-name="ufa5d" d="M 342.5 247.15039 L 342.5 415.15039 L 43.25 415.15039 L 43.25 440.34961 L 342.5 440.34961 L 342.5 564.25 L 342.5 580 L 342.5 601.70117 L 404.93359 589.79883 C 436.96232 583.63687 438.82989 567.24993 405.5 556.83398 L 405.5 272.34961 L 342.5 247.15039 z M 594.5 247.15039 L 594.5 564.25 L 594.5 580 L 594.5 601.70117 L 656.93359 589.79883 C 688.96232 583.63687 690.82989 567.24993 657.5 556.83398 L 657.5 440.34961 L 843.34961 440.34961 L 893.75 490.75 L 956.75 440.34961 L 956.75 415.15039 L 657.5 415.15039 L 657.5 272.34961 L 594.5 247.15039 z"/>
<glyph glyph-name="u20000-jv" d="M 143 -31.099609 L 143 480.25 L 201.80078 450.84961 L 473.75 450.84961 L 473.75 756.40039 L 80 756.40039 L 80 781.59961 L 806.59961 781.59961 L 857 832 L 920 781.59961 L 920 756.40039 L 536.75 756.40039 L 536.75 385.75 L 473.75 360.55078 L 473.75 425.65039 L 206 425.65039 L 206 57.099609 L 775.09961 57.099609 L 825.5 107.5 L 888.5 57.099609 L 888.5 31.900391 L 206 31.900391 L 206 -5.9003906 L 143 -31.099609 z"/>
<glyph glyph-name="u20000-ue0101" d="M 143 -36.349609 L 143 417.25 L 201.80078 387.84961 L 468.5 387.84961 L 468.5 640.90039 L 80 640.90039 L 80 666.09961 L 468.5 666.09961 L 468.5 805.75 L 468.5 821.5 L 468.5 843.20117 L 530.93359 831.29883 C 562.86375 825.15583 564.51051 808.89709 531.5 798.47656 L 531.5 666.09961 L 806.59961 666.09961 L 857 716.5 L 920 666.09961 L 920 640.90039 L 531.5 640.90039 L 531.5 322.75 L 468.5 297.55078 L 468.5 362.65039 L 206 362.65039 L 206 51.849609 L 780.34961 51.849609 L 830.75 102.25 L 893.75 51.849609 L 893.75 26.650391 L 206 26.650391 L 206 -11.150391 L 143 -36.349609 z"/>
<glyph glyph-name="u20000-ue0102" d="M 143 -43.123047 L 143 395.38281 L 201.79688 365.98438 L 473.75 365.98438 L 473.75 601.78711 L 95.75 601.78711 L 95.75 626.98828 L 817.10156 626.98828 L 867.5 677.38672 L 930.5 626.98828 L 930.5 601.78711 L 536.75 601.78711 L 536.75 300.88281 L 473.75 275.68359 L 473.75 340.7832 L 206 340.7832 L 206 45.078125 L 775.10156 45.078125 L 825.5 95.476562 L 888.5 45.078125 L 888.5 19.876953 L 206 19.876953 L 206 -17.921875 L 143 -43.123047 z M 500 706 C 469.39653 706.23029 444.875 730.37828 444.875 761.125 C 444.875 791.87172 469.39653 816.01971 500 816.25 C 530.60347 816.01971 555.125 791.87172 555.125 761.125 C 555.125 730.37828 530.60347 706.23029 500 706 z"/>
</font>
先ほどと違ってsvgにおいて各グリフにunicode属性ではなくglyph-name属性を指定していることに注意。system.svgではType1への変換を経由しているのでunicodeを指定してそれをグリフ名として使う必要があったが、svgフォントを直接指定する場合はglyph-nameがかわりに使えるようである(unicodeでも探してくれるかもしれないが確かめていない)。「glyph-00001」のようにunicodeとは全く無関係の識別子でも自由に使えるので便利である。ここではglyph-nameとしてGlyphWikiでのグリフ名を使用している(例えばu8279-jはu8279-j (艹) - GlyphWikiの字形である)。
またmapファイルのFDArray要素の名前としてはNazoMin-Ideographsと、先ほどのSystemとは異なりIdeographsという識別子を使っている。これも後で使う。
今後の説明でも必要になるので上記で例として使用している字について一通り説明しておこう。以下がtx -pdf kanjisample.svg > kanjisample.pdfで出力されるpdfである。
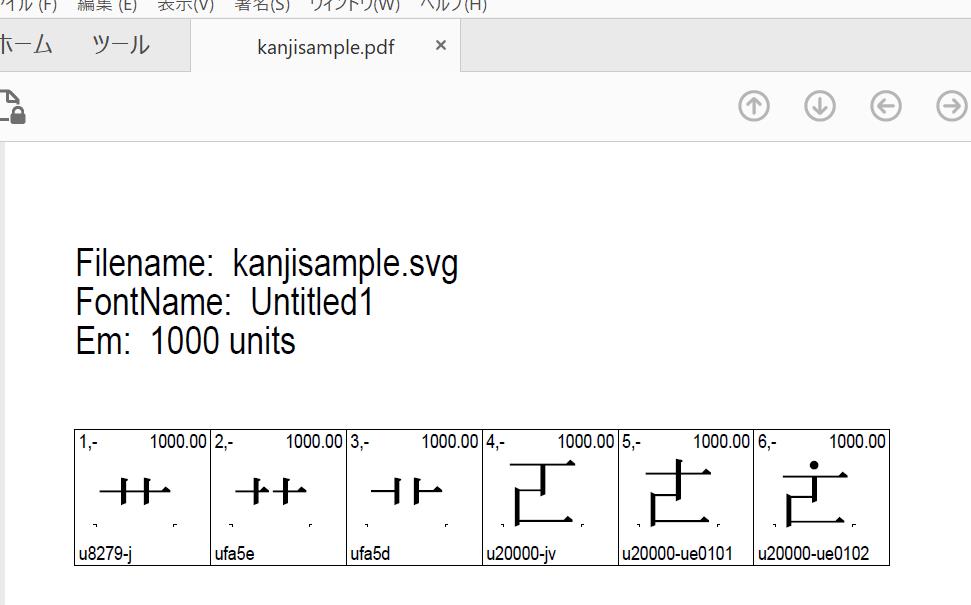
見ての通り、最初の3文字は「くさかんむり」であるが、微妙に字形が異なる。
この3グリフは(記事執筆時点の)GlyphWikiにおいてそれぞれ以下のUnicodeコードポイントや異体字シーケンスが割り当てられている。(ここでは異体字について詳しく解説はしないが、以下の意味がすんなり理解できるようになれば異体字マスターといっても過言ではない(?)。「異体字セレクタ」「Adobe-Japan1」「CJK部首補助」などの語で適宜検索すること。)
- つながった字形…CJK部首補助
U+2EBE(⺾)、CJK統合漢字U+8279(艹)、Adobe-Japan1コレクションのIVSU+8279 U+E0100(艹󠄀)、Moji_Joho及びHanyo-DenshiコレクションのIVSU+8279 U+E0105(艹󠄅) - 「十」が2つの字形…CJK部首補助
U+2EBF(⺿)、CJK互換漢字U+FA5E(艹)、それに対応するSVSであるU+8279 U+FE01(艹︁)、Adobe-Japan1コレクションのIVSU+8279 U+E0102(艹󠄂)、Moji_Joho及びHanyo-DenshiコレクションのIVSU+8279 U+E0104(艹󠄄) - 「T」が背中合わせの字形…CJK部首補助
U+2EC0(⻀)、CJK互換漢字U+FA5D(艹)、それに対応するSVSであるU+8279 U+FE00(艹︀)、Adobe-Japan1コレクションのIVSU+8279 U+E0101(艹󠄁)、Moji_Joho及びHanyo-DenshiコレクションのIVSU+8279 U+E0103(艹󠄃)
以上の通りこれらは全てAdobe-Japan1コレクションに含まれている字であるため、游明朝などAdobe-Japan1準拠のフォントでは、上記のうち「Moji_Joho及びHanyo-DenshiコレクションのIVS」となっているもの以外は全て正しく表示できるはずである。カッコ内をコピペして試してみるとよい。
謎乃明朝では、現時点では(2フォントに分ける前提で)グリフ数に多少余裕があるので、一応Adobe-Japan1に従ってCID+14197, CID+14198, CID+14199をそれぞれ割り当てているが、Adobe-Japan1準拠のフォントを作るのでなければこうする必要はなく、CID+1から順に漢字で埋めても構わないはず。
その次の3文字は、U+20000(𠀀)の異体字である。Unicodeの20000-2FFFFは「追加漢字面」(SIP)と呼ばれ、日本で普段使われることはない漢字が大半である(「𩸽(ほっけ)」など例外もある)。この範囲の文字を例に含めたのは、BMP外のUnicode文字はサポートが不十分なソフトも多い中で、AFDKOを使えばきちんと対応できる、ということを示すためである。
こちらの割り当ては先ほどよりはずいぶん単純である。GlyphWikiでは、最初のu20000-jvがU+20000とU+20000 U+E0100、次のu20000-ue0101がU+20000 U+E0101、その次のu20000-ue0102がU+20000 U+E0102で使われている(後の2つは名前からして当然であるが)。これらは全てMoji_JohoコレクションのIVS異体字であり、U+20000自体もAdobe-Japan1には含まれていないので、正しく表示するには謎乃明朝、花園明朝あるいはIPAmj明朝などが必要だろう。ここでは一応、Adobe-Japan1のCID(現在23059まで定義されている)と被らないよう、24000以降を割り当てている(もちろんそうする必要はない。)
なお、ここではSVS・IVSに対応したフォントを作成するが、Variation Selectorは特殊文字なので、それ自体にグリフを割り当てる必要はない。
出力
ここまで理解したら、以下のようにコマンドを実際に実行してみよう。
$ mergefonts -cid cidfontinfo merged.pfa system.map system.pfa kanjisample.map kanjisample.svg
mergefonts: --- system.pfa
mergefonts: (cfw) unhinted <cid-0>
Adding font dict 0 from system.pfa.
mergefonts: --- kanjisample.svg
mergefonts: (cfw) unhinted <cid-14197>
mergefonts: (cfw) unhinted <cid-14198>
mergefonts: (cfw) unhinted <cid-14199>
mergefonts: (cfw) unhinted <cid-24000>
Adding font dict 1 from kanjisample.svg.
mergefonts: (cfw) There are 2 additional reports of 'unhinted'.
mergefonts: --- merged.pfa
mergefonts: (cfr) /BlueValues missing: FD[1]
unhintedや/BlueValues missing: FD[1]などとwarning/errorが出ているが、あとでヒントを追加するので無視でよい(多分)(SVGに直接BlueValuesを追加する方法があってもおかしくはないと思うが見つけられなかった)。
生成されたmerged.pfaを再びtxでpdfにしてみると以下のようになる。
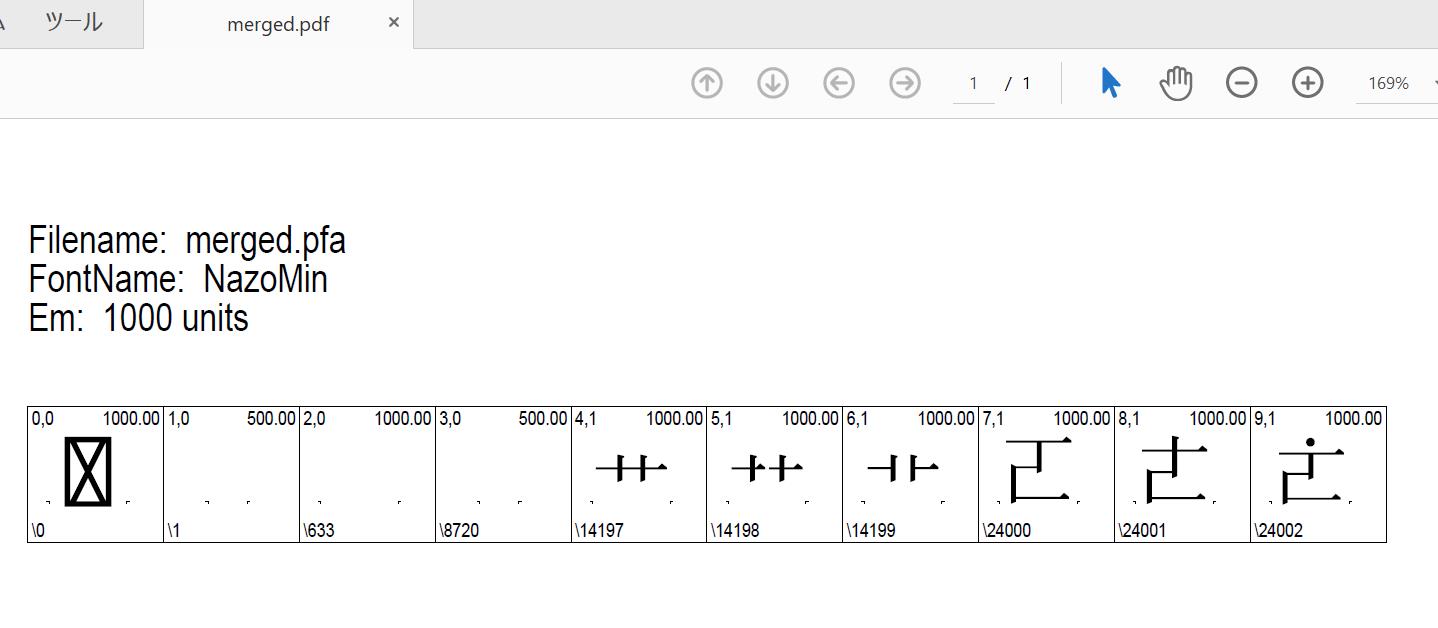
このように、各CIDに意図した字形が割り当てられていることがわかるだろう。しかし、それらのCIDがどの文字に対応するものなのかという情報は全く含まれていないので、これはまだ実際に使用できるフォントではない。
ヒントの付加
次に、このフォントにヒントを付加する。ヒントというのは、フォントをラスタライズ(実際にピクセルに変換して描画)する際に、線の太さなどを調節して見やすくするための機能であり、特に小さいサイズで表示したときの見た目に大きく影響する。日本語情報はあまりないが、Fontforge関連でいくつか見つけることができる。またBlueValuesやStdHWなど個々の値の仕様に関してはhttps://kikakurui.com/x4/X4163-1994-01.htmlで日本語で読める。個人的にもあまりヒントの動作についてはよくわかっていないので、ここでは最低限のやり方だけ述べる。
ちなみにこの記事では扱わないがAFDKOにはrotatefontというグリフを(ヒント情報含めて)自動で回転させてくれるコマンドがあり、これを使った場合にもその後で改めてpsautohintを実行するのが望ましいようである(参考 :アンチックフォントを作る: グリフの変形と合成)。
hitcidfont.plを使う
ヒントの付加はpsautohintというプログラムで行うが、psautohintが動作するためには、BlueValuesという値だけは最低限手動で設定しなければいけないようである。そこで、perl-scripts/hintcidfont.pl at master · adobe-type-tools/perl-scriptsを用いて、先ほど生成したmerged.pfaにBlueValues(やその他、必須ではないパラメータ)を付加する。
このスクリプトは(今回であれば)以下のように使用する。
hintcidfont.pl hintparam.txt < merged.pfa > merged_out.pfa
前述の通りpfaフォント(ファイルの先頭がああいう感じのやつ)以外には使えないようである。このhintparam.txtがBlueValuesなどを指定するファイルで、ここで先ほどFDArray要素の名前で使用したSystemやIdeographsを使用する。
System
/BlueValues [-250 -250 1100 1100] def
/StdHW [100] def
/StdVW [100] def
Ideographs
/BlueValues [-100 -200 1100 1100] def
/StdHW [70] def
/StdVW [100] def
/StemSnapH [70 80 60 90 50 40] def
/StemSnapV [80 70 90 60 100 50 110] def
このように、FDArray要素ごとに自動ヒント付けのための情報を付加できる。
前述のようにBlueValuesは最低限必要で、これは確かフォントがラスタ化されるときの最大のバウンディングボックスを指定するものなので、該当のFDArrayに含まれるグリフのバウンディングボックスより大きければ大丈夫だと思う。今回のように1000x1000で漢字のみ入れるような場合は適当に[-250 -250 1100 1100]などとしておけばよいはず。
StdHWとStdVWは水平方向のステムの(垂直方向の)幅と垂直方向のステムの(水平方向の)幅の目安(?)をそれぞれ指定するものである。明朝なら横線のほうが細いということで、ここでは何となくStdHWを70、StdVWを100としているが、効果がどうなのかはよくわかっていない。StemSnapHとStemSnapVは、StdHWとStdVWと似ているが、より細かい精度でガイドラインを設定するような感じのやつである。あまり情報がなくてよくわからないので、かなり適当に設定していて、本当は小さい順に並べる必要があったりするのかもしれない。
まあ言ってしまえば、見た目を追求するなら本来は手動でヒント付けを行うべきである(多分)。他の設定例はhttps://ccjktype.fonts.adobe.com/wp-content/uploads/2012/06/afdko-lunde-20120625.pdf なども参照。
上手くいけば、以下のような出力とともにこれらの値が付加されたpfaファイルが生成される。テキストエディタで開いてみると、pfaファイルの上の方に/BlueValues [-250 -250 1100 1100] defなどと書きこまれているのがわかる。
$ hintcidfont.pl hintparam.txt < merged.pfa > merged_out.pfa
Detected CIDFontName: NazoMin
Modifying System hinting parameters...
Modifying Ideographs hinting parameters...
ここまでの記事に従っていれば大丈夫かと思うが、何も出なかったらおそらくどこかが間違っているのでpfaファイルの中身やスクリプトのソースを読んでみるなどして確認すること。
psautohintの実行
では次にpsautohintを実行する。オプションなどは筆者がよくわかっていないので、今回は以下を実行するだけである。
psautohint merged_out.pfa -o hinted.pfa
今回はグリフ数が少ないのですぐに終わるが、数万グリフあるとなると数分ほどかかる処理である。
手元ではたまにERROR: cid51649: Possible loop in element that goes from 109 46 to 109 47. Please check.(あるいは稀にERROR: cid45515: Check for duplicate subpath at 128 758)などと出る字もあるのだが特に見た目は問題無さそうなので無視している。
makeotfの準備
ここまででグリフのデータは完成したので、実際に使えるフォントにするためのmakeotfの実行に向けて準備を行う。
基本的には、それぞれの文字(Unicode符号位置)でどのCIDを使用するかというCMapが最も重要で、これさえあれば一通り使えるフォントにはなるが、ここでは(先ほど説明した)異体字セレクタも使えるようにSequenceファイルも使用する。OpenType featureに関しては(自分があまりよくわかっていないので)フォントの高さなど最低限の設定のみ行う。他にもGSUB・GPOSをはじめ様々な面白いfeatureがあるので調べてみてほしい。また、フォント名の設定のためFontMenuNameDBというファイルも使用する。
これらについてはAFDKO入門《CIDキー方式のOpenTypeフォントの作り方》 後篇:makeotf - しろもじメモランダムも参考になる。またhttps://github.com/adobe-fonts/source-han-sansやhttps://github.com/adobe-type-tools/Adobe-Japan1にも例がある。
FontMenuNameDB
[NazoMin]
f=NazonoMincho
s=Regular
l=NazonoMincho Regular
f=3,1,0x411,\8B0E\4E43\660E\671D
s=3,1,0x411,Regular
l=3,1,0x411,\8B0E\4E43\660E\671D Regular
f=1,1,11,\93\E4\94\54\96\BE\92\A9
s=1,1,11,Regular
l=1,1,11,\93\E4\94\54\96\BE\92\A9 Regular
このように、先ほど使用したPostScript名であるNazoMinを先頭に書き、フォント名を設定する。
\8B0E\4E43\660E\671Dと\93\E4\94\54\96\BE\92\A9はそれぞれWinとMacのエンコーディングで「謎乃明朝」を表す。少なくともWindowsに関しては、UTF-16のサロゲートペアを用いればBMP外文字でも指定できるようである(例えば先ほどのU+20000なら\D840\DC00)が、やめておいた方が無難だろう。
CMap
CMapは、各UnicodeのためにどのCIDを使用するかを指定するもので、フォントの根幹部分を決める重要なファイルである。日本語の「、。」のような縦と横で字形(位置)が異なる文字のために縦書き用CMapが必要なこともあるが、今回は漢字だけなので、とりあえず横書きだけ指定しておけばあとはmakeotfがやってくれる。
%!PS-Adobe-3.0 Resource-CMap
%%DocumentNeededResources: ProcSet (CIDInit)
%%IncludeResource: ProcSet (CIDInit)
%%BeginResource: CMap (NazoMinCMAP-UTF32-H)
%%Title: (NazoMinCMAP-UTF32-H Adobe Identity 0)
%%Version: 2.004
%%Copyright: -----------------------------------------------------------
%%Copyright: (省略)
%%Copyright: -----------------------------------------------------------
%%EndComments
/CIDInit /ProcSet findresource begin
12 dict begin
begincmap
/CIDSystemInfo 3 dict dup begin
/Registry (Adobe) def
/Ordering (Identity) def
/Supplement 0 def
end def
/CMapName /NazoMinCMAP-UTF32-H def
/CMapVersion 2.004 def
/CMapType 1 def
/WMode 0 def
1 begincodespacerange
<00000000> <0010FFFF>
endcodespacerange
1 beginnotdefrange
<00000000> <0000001f> 1
endnotdefrange
6 begincidchar
<00000020> 1
<00003000> 633
<00008279> 14197
<0000fa5d> 14199
<0000fa5e> 14198
<00020000> 24000
endcidchar
1 begincidrange
<00002ebe> <00002ec0> 14197
endcidrange
endcmap
CMapName currentdict /CMap defineresource pop
end
end
%%EndResource
%%EOF
このような感じで、unicode位置(このファイルはUTF32版である)からCIDへの対応関係を記述する。
なお、begincidrangeはbegincidcharがCID・Unicode位置ともに連続しているときに楽に指定するためのものである。また、begincidcharやbegincidrangeによる1つのブロックまでには最大100個(上記では1や6になっている)までしか情報を入れられない。従って、機械的にCMapを生成するときは、以下のように全て1 begincidchar ... endcidcharで指定してしまうのが楽である。
...
1 begincidchar
<00008279> 14197
endcidchar
1 begincidchar
<00002ebe> 14197
endcidchar
...
その上で、サイズを削減したいときは、perl-scripts/cmap-tool.pl at master · adobe-type-tools/perl-scriptsを使うと良い感じにbegincidrangeにした上で100個ずつにまとめてくれる。
Sequenceファイル
今回は以下のものを使用する。先ほど解説した通りに「CJK統合漢字+異体字セレクタ」の組が該当CIDを参照していることを確認せよ。
ちなみに、異体字セレクタが付けられている元の字(以下ならU+8279とU+20000)自体がフォントに含まれていないとたしか異体字も使えないはずなのでそこは注意。
8279 E0100; AJ1; CID+14197
8279 E0105; AJ1; CID+14197
8279 E0104; AJ1; CID+14198
8279 FE01; AJ1; CID+14198
8279 E0102; AJ1; CID+14198
8279 E0101; AJ1; CID+14199
8279 E0103; AJ1; CID+14199
8279 FE00; AJ1; CID+14199
20000 E0100; AJ1; CID+24000
20000 E0101; AJ1; CID+24001
20000 E0102; AJ1; CID+24002
このファイル形式はAFDKOやOpenTypeフォント自体に由来するものであるというよりは多分UnicodeのIVDに含まれるSequenceファイルに由来するものであるように思われる。SourceHanSansやAdobe-Japan1のリポジトリにある例ではそれに従って中央の列にAdobe-Japan1やStandardized_Variantsなどと律儀に書いてあるが、AFDKOが読むのは実際には第1のシーケンスと第3列のCID番号だけと思われるので、このように適当にAJ1などと書いてファイル容量をケチっておいても問題はなさそうだった。
featureファイル
このファイルによって完成品のフォント名などが決められる。
ほぼAFDKO入門《CIDキー方式のOpenTypeフォントの作り方》 後篇:makeotf - しろもじメモランダムを参考に、最低限の内容だけ入れている。
table head {
FontRevision 0.004;
} head;
table hhea {
CaretOffset 0;
Ascender 880;
Descender -120;
LineGap 1000;
} hhea;
table OS/2 {
FSType 0;
Panose 2 # Latin, Text
11 # Normal Sans
4 # Thin
9 # Monospaced
0 0 0 0 0 0; # Any
UnicodeRange
0 1 2 5 6 7 9
31
32 33 34 35 36 37 38 39
42 43 44 45 46 47
48
49 # Hiragana
50 # Katakana
54 55 57
59 # CJK Unified Ideographs
61 # CJK Strokes, CJK Compatibility Ideographs (Supplement)
65 68
91 # Variation Selectors
;
CodePageRange
1252 # Latin 1
1250 # Latin 2
932 # JIS/Japan
936 # Chinese: Simplified chars—PRC and Singapore
949 # Korean Wansung
950 # Chinese: Traditional chars—Taiwan and Hong Kong
1361 # Korean Johab
;
TypoAscender 880;
TypoDescender -120;
TypoLineGap 1000;
winAscent 1000;
winDescent 100;
XHeight 0;
CapHeight 0;
WeightClass 400;
WidthClass 5; # Full width
Vendor "YHVH";
} OS/2;
table vhea {
VertTypoAscender 500;
VertTypoDescender -500;
VertTypoLineGap 1000;
} vhea;
feature vrt2 {
sub \1 by \8720;
} vrt2;
feature vert {
sub \1 by \8720;
} vert;
詳しくは他サイトに譲る。Ascender/Descenderによりフォントの高さ・深さを指定している(880-(-120)でちょうど1000になっていることを確認せよ)。winAscentとwinDescentはWindows限定のようだが、少なくともこれを変えると手元ではWordでのフォント高さが変わるので重要そうである(この設定例はかなり小さめである)。FontRevisionは好きに設定してよい。わからないときは、ttx(txではない)で既存フォントのテーブルを見てみるのもよいだろう。
UnicodeRangeやCodePageRangeは、フォントがどのような言語・文字集合に対応しているかの参考にされるのだと思うが、少なくともフォント名を自分で指定してこのフォントを使う分にはあまり影響しない部分かと思われる。実際には一文字も収録していないUnicode範囲をこんな大量に指定するのはやめた方がよさそうである。
vrt2の部分は前述の花園明朝OTを0.510に更新、IVD 2012-03-02版に対応 - しろもじメモランダムを参考にしたものである。vertは勝手に同じ内容でつけてみた。
makeotfの実行
ここまでできたら
makeotf -f hinted.pfa -ff features -o final.otf -ch NazoMinCMAP-UTF32-H -ci sequences.txt -mf FontMenuNameDB
としてフォントをビルドしてみよう。なお、FontMenuNameDBとfeaturesはそれぞれAFDKOが探すデフォルトの名前なので、別の名前を使わない限りは指定しなくてもよい。Built development mode font "…./final.otf"などと出ればめでたく成功である。ちなみに-rオプションを付けるとreleaseモードになり、”Built release mode font”と出る。多少時間がかかるもののサイズが減るなどする。
あとはインストールしてちゃんと文字が出るか確かめればよい。Wordで確かめているとインストール直後はフォントの色々な情報(特に高さなど)がうまく読み込まれない場合があるので、何かおかしいと思ったらOffice系のソフトを一旦全て終了するなどしてからまた起動するのがよい。
TrueTypeへの変換
AFDKOが生成するのはPostScriptアウトラインのOpenTypeフォントであるから、曲線データには3次ベジェ曲線が用いられる。TrueTypeでは2次ベジェ曲線しか使えないので、3次ベジェ曲線→2次ベジェ曲線の変換が必要である。これは自明な変換ではなく近似が必要であるが、AFDKOにはこれをやってくれるotf2ttfというコマンドがある。シンプルにotf2ttf final.otfとすればfinal.ttfというTrueTypeフォントが出力される。
その他参考
その他、フォントに関連する記事としては、Webブラウザ(Chrome)とWordの「検索と置換」についても参考になるだろう。
CSSで謎乃明朝
IVSなどがあるので(body:{}などに書く)font-family:のところではNazoMinを先に指定すること。
@font-face {
font-family: "NazoMin";
src: local("謎乃明朝 Regular");
unicode-range: U+3400-U+4DFF, U+2F800-2FFFF, U+30000-3FFFF;
}
@font-face {
font-family: "NazoMin+";
src: local("謎乃明朝+ Regular");
unicode-range: U+20000-2F7FF;
}